During these past few weeks, I’ve had a chance to play around quite a bit with the soon-to-be-1.0 Akka Streams module and I’ve been looking for a concrete reason to write about why this is an important milestone for the stream processing ecosystem. It just so happens that this week, we were conducting an experiment related to Twitter follower analysis that required pulling a few million public user profiles of followers of large Twitter accounts and the ability to do so in a relatively short amount of time. I decided to use Akka Streams for this project to see how far I could push it in a real world scenario.
App Skeleton
I decided to start with a regular Scala command line app and hardcode the Twitter ID of the person whose followers’ profiles we were attempting to retrieve (since this is going to be throwaway code just for the sake of the experiment). The only dependencies were akka-actor, akka-stream-experimental and twitter4j-core.
Twitter API Interaction
We need some way to call the Twitter API primarily for two reasons:
1) Fetch all follower IDs of a given userID
2) Fetch a user profile given a userID.
Any call made to Twiter’s API needs an authenticated twitter4j.Twitter object. Given a set of credentials, a twitter4j.Twitter object is constructed as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Given a user, return all followers
Using the TwitterClient, we can fetch a user’s profile and list of followers with the following TwitterHelpers object:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
Akka Boilerplate
With the Twitter interactions out of the way, we can create a new command line app using:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
At this point, we have a working app that can be invoked using sbt run. Let’s get started on the Akka Streams bit.
The Pipeline
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Breaking down the flow line by line
1
| |
turns the Set[Long] of follower IDs into an Akka Streams Source.
1 2 3 | |
The group, map and mapConcat transform the stream of Longs into a stream of twitter4j.User objects.
1
| |
And finally, the user objects are piped into a Sink which adds them to our output queue.
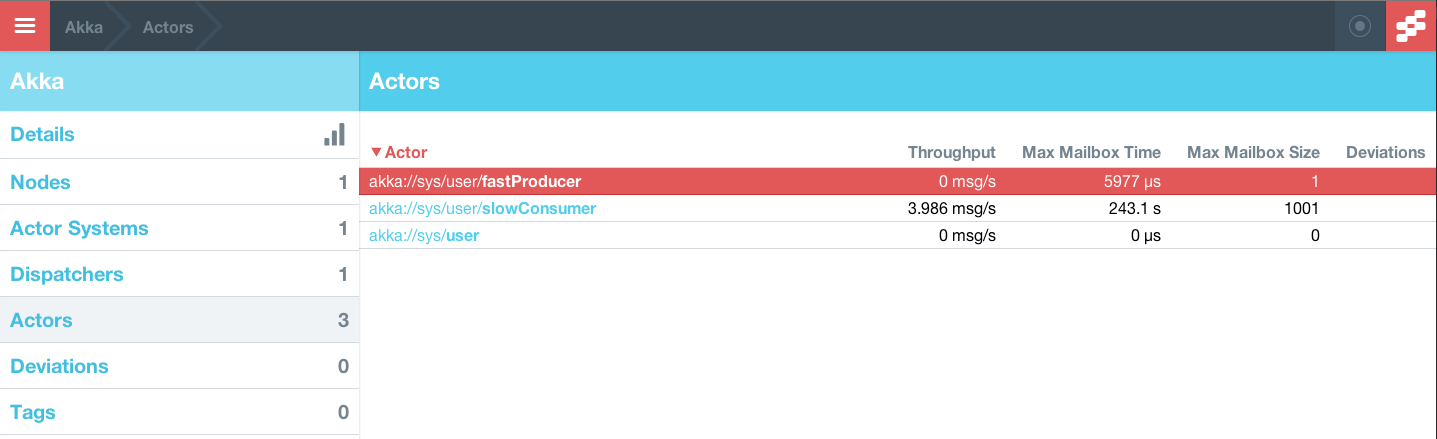
Run 1 – 12,199 profiles in 108s
Running this flow takes 108 seconds to retrieve 12,199 user profiles from Twitter.

Run 2 – 12,200 profiles in 11s
Modifying the flow slightly to allow for more concurrency helps bring down the total time taken by a large value. The obvious bottleneck in the flow implementation is the synchronous fetching of user profiles in the stage where User IDs are mapped to User profile objects. Replacing the
1
| |
with
1
| |
reduces the time taken from 108s to 11s. That’s almost 10x faster with a single line change!

(It looks like Erik Meijer has gained a follower between our two runs).
Run 3 – 1.22M profiles in 256s
Netflix USA has approximately 1.22M followers. Fetching followers for this account took 256s.

Run 4 – 2.88M profiles in 647s
Twitter co-founder Jack Dorsey has 2.88M followers and the pipeline processed them in 647 seconds.

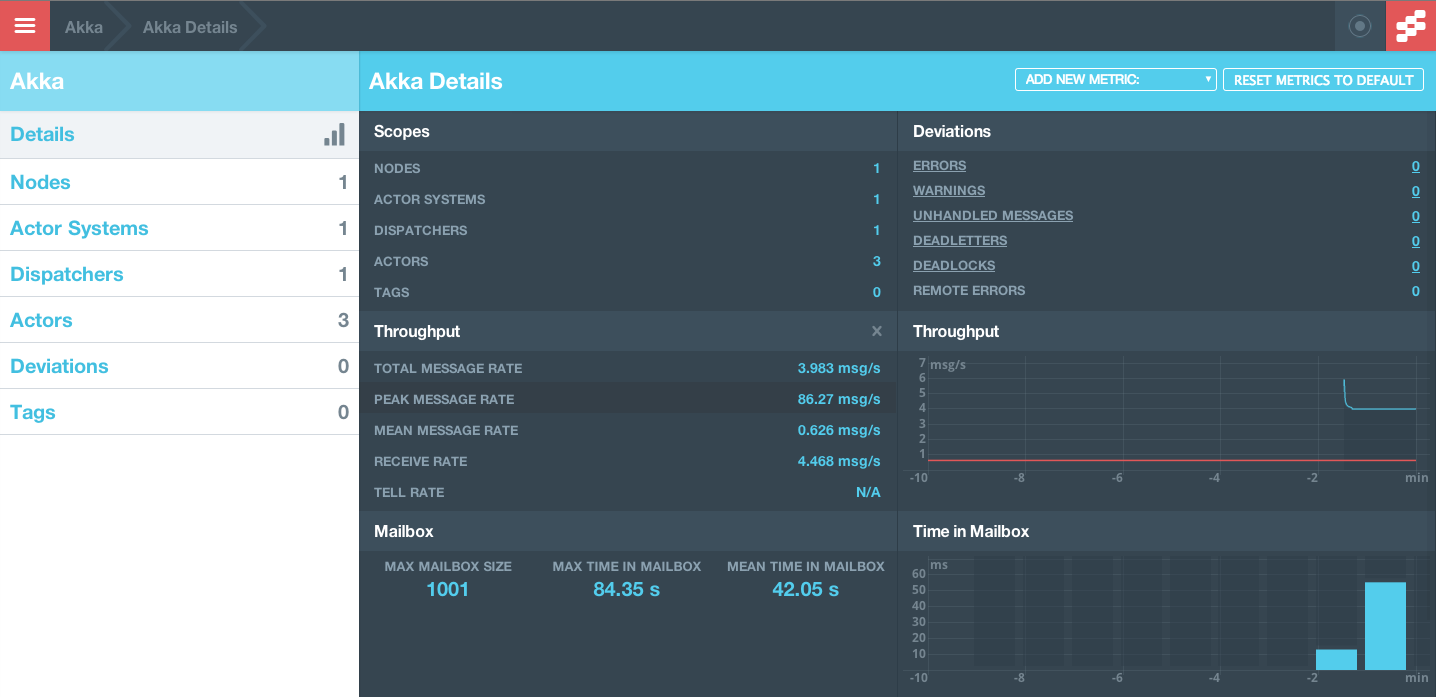
Since Netflix (1.22M) was processed in 256s and Jack (2.88M) was processed in ~650s, it doesn’t look like the pipeline is showing any signs of exhaustion as larger accounts are being processed.
Final Thoughts
Before Akka Streams, creating a flow like this would require hand coding each stage as an actor, manually wiring everything up and carefully managing backpressure using a hybrid push/pull system alongwith finely configured timeouts and inbox sizes. Having worked on many such systems at CrowdRiff, my experience so far has been mostly positive. Akka delivers exactly what it promises – an easy way to think about concurrency, excellent performance and a great toolkit to build distributed systems. However, once built, these systems often tend to be very complex and common changes like adding stages to the pipeline or modifying existing stages have to be done very carefully (despite unit tests!). Akka Streams takes this to a whole new level by allowing the user to create arbitrary flows (check out stream graphs) in simple and easy to read manner AND managing the backpressure for you! The large quantity of awesome in this module is certainly appreciated by me and my team – many thanks to the Akka folks and everyone who contributed to the Reactive Streams project. Happy hAkking!