A few days ago, I was officially introduced to Couchbase at a Toronto Hadoop User Group meetup. I say “officially” because I’ve known about some Couchbase use-cases / pros and cons on a high level since v1.8, but never really had the time to look at it in detail.
As the presentation progressed, it got me interested in actually tinkering around with a Couchbase cluster (kudos to Don Pinto). My first instinct was to head over to the Docker Registry and do a quick search for couchbase. Using the dustin/couchbase image, I was able to get a 5-node cluster running in under 5 minutes.
Run 5 containers
1 2 3 4 5 | |
Find Container IPs
Once the containers were up, I used docker inspect to find their internal IPs (usually in the 172.17.x.x range). For example, docker inspect cb1 returns
1 2 3 4 5 6 7 8 9 10 11 12 | |
Update: Nathan LeClaire from Docker was kind enough to write up a quick script that combines these two steps:
1 2 3 4 5 6 7 8 9 | |
Setup Cluster using WebUI
If cb1 is at 172.17.0.27, then the Couchbase management interface comes up at http://172.17.0.27:8091 and the default credentials are:
1 2 | |
Once you’re in, setting up a cluster is as easy as clicking “Add Server” and giving it the IPs of the other containers. As soon as you add a new server to the cluster, Couchbase will prompt you to run a “Cluster Rebalance” operation – hold off until you’ve added all 5 nodes and then run the rebalance.
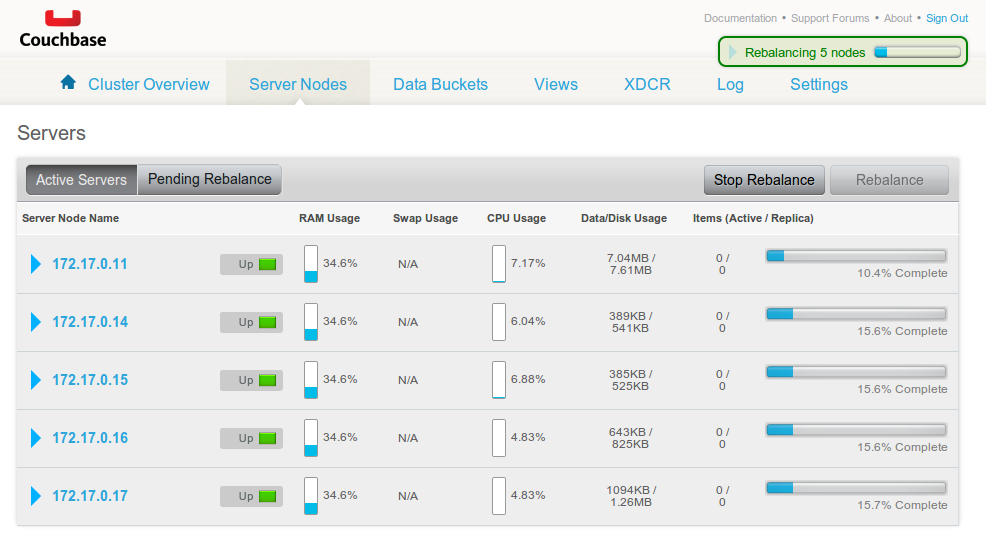
Push some data into the cluster
Once the cluster was up, I wanted to get a feel for how the WebUI works so I wrote this script to grab some data from our existing cluster of JSON-store-that-I-am-too-ashamed-to-mention and added it to Couchbase:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
The Couchbase python client depends on libcouchbase. Once those two were installed, and the twitter_starbucks bucket had been created in Couchbase, I was able to load ~100k JSON documents in a matter of minutes.